reinforcement learning
132 статей
 1ч 33м
1ч 33м♟ Брайан Ю: «Как мы учим компьютеры играть и думать»
 45 мин
45 мин🚀 Опыт Cursor и Fireworks: распределенная инфраструктура для RL-обучения Composer 2
 1ч 13м
1ч 13м🧠 Лекция Stanford CS221: От табличных методов к Actor-Critic
 1ч 13м
1ч 13мТеория игр: Minimax, Alpha-Beta и поиск оптимальной стратегии
 1ч 18м
1ч 18м🤖 От случайного блуждания до Q-Learning: как ИИ учится на своих ошибках
 20 мин
20 мин🧠 Вес Рот о Grok 4.20: «Четыре агента спорят друг с другом перед ответом»
 1ч 22м
1ч 22м🤖 Филип Исола: «Поиск — это новый двигатель глубокого обучения»
 1ч 12м
1ч 12мDREAM: как научить ИИ исследовать и обучаться эффективнее
 1ч 09м
1ч 09м🧠 Как Meta-RL позволяет агентам адаптироваться к новым задачам „на лету“
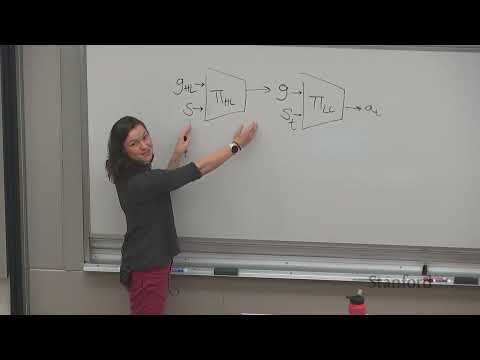 1ч 09м
1ч 09м🏗 Stanford CS224R: Как иерархический ИИ решает задачи с длинным горизонтом
 50 мин
50 минАникайт из Стэнфорда: «Почему ваше Q-обучение нестабильно?»
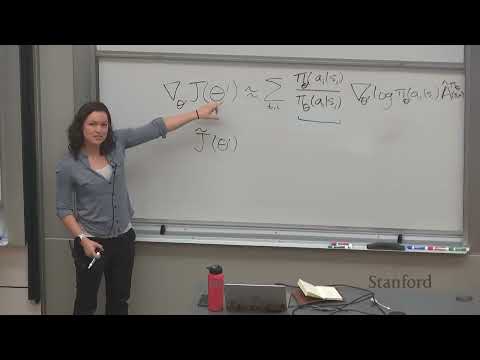 1ч 09м
1ч 09м⚖ Stanford CS224R: PPO и SAC как стандарты обучения с подкреплением
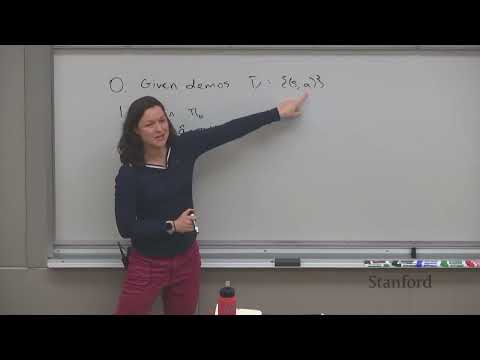 1ч 07м
1ч 07м🤖 Имитационное обучение: почему простого копирования действий недостаточно
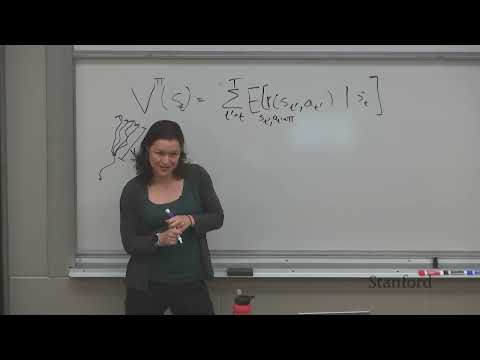 1ч 03м
1ч 03м🔄 Stanford Online: «Методы Actor-Critic — база для обучения LLM и роботов»
 49 мин
49 мин⚖ Лекция в Стэнфорде: развитие интеллекта роботов через RL
 1ч 16м
1ч 16м🧠 Джонатан Сиддарт из Turing: почему 99% интеллектуального труда будет автоматизировано, а традиционный SaaS исчезнет
 18 мин
18 мин🎓 Стэнфордский ИИ-путеводитель: как выбрать подходящие курсы и построить карьеру в Deep Learning
 58 мин
58 мин🧠 Шеф по ИИ в Cohere: почему законы масштабирования выстоят, а термин «экзистенциальный риск» пора запретить
58 мин🧠 Джоэль Пино из Cohere: почему законы масштабирования работают и как ИИ повысит продуктивность в 10 раз
 1ч 03м
1ч 03м🤖 Пирамида данных для манипуляций: как Stanford обучает роботов сложному поведению
 40 мин
40 мин🧬 Уэс Рот и Дилан: «ИИ помогает нам понять природу сознания»
 1ч 11м
1ч 11м💻 Марк Андриссен и Амджад Масад: «Английский — это новый язык программирования»
 1ч 30м
1ч 30м📉 Натан Лабенц: «Худшая ошибка — недооценить, как далеко зайдет ИИ»
 55 мин
55 мин🛠 Как ИИ-агенты меняют программирование: взгляд экспертов из Anthropic и Стэнфорда
 1ч 19м
1ч 19м💻 Мария Ша о будущем программирования и обучении нейросетей
 54 мин
54 мин🚀 Эван Рейзер (Poolside): «Обучение на исполнении кода — это путь к созданию AGI»
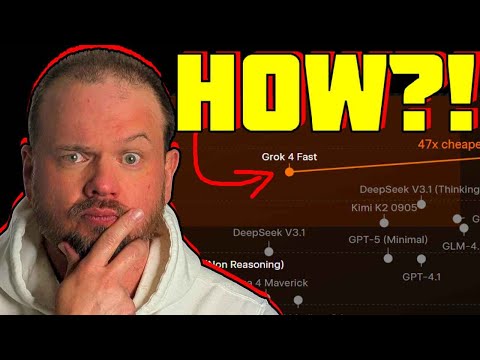 29 мин
29 мин🚀 Почему Grok 4 Fast в 47 раз дешевле конкурентов: разбор стратегии xAI
 43 мин
43 мин🚀 Картик из Sierra AI о будущем агентных систем: «Агенты должны учиться через чтение»
 50 мин
50 мин🤝 Скотт Ву (Cognition) о сделке с Windsurf и будущем ИИ-агентов
 2ч 54м
2ч 54м🤖 Восемь лет до сингулярности: как ИИ построит «Потемкинскую деревню»
 17 мин
17 мин🚀 Уэс Рот о новой революции в RL: «Эра компактных и дешевых учителей ИИ настала»
 11 мин
11 мин🚀 Демис Хассабис о «интеллектуальном взрыве» и будущем самосовершенствующегося ИИ
 1ч 06м
1ч 06м🧠 Дэнни Чжоу из Google DeepMind: как большие языковые модели на самом деле учатся рассуждать
 26 мин
26 мин⚔ Уэс Рот: «Будущее программирования станет похоже на игру в Starcraft»
 39 мин
39 мин🎙 Уэс Рот и экс-директора Google: как самообучение ИИ без участия человека изменит индустрию
39 мин🧠 Уэс Рот и экс-директора Google об изнанке ИИ: почему модели больше нельзя контролировать
 40 мин
40 мин🤖 Absolute Zero: как ИИ учится программировать без людей и почему ученых пугает «uh-oh момент»
 35 мин
35 минУэс Рот о ChatGPT: «Почему ИИ начал нам подлизываться?»
 1ч 12м
1ч 12м🚀 Карина Нгуен из OpenAI: «В будущем интерфейсы программ будут генерироваться на лету под каждого пользователя»
1ч 12м🚀 Карина Нгуен из OpenAI: Как RL превращает ИИ из чат-бота в полноценного напарника
 1ч 09м
1ч 09м📅 Кэл Ньюпорт разобрал секреты продуктивности Сэма Альтмана и будущее ИИ
 1ч 01м
1ч 01м🧠 От «детских» данных до нейронауки: лекция Stanford CS25
 59 мин
59 мин🧠 Педро Домингос: «Современный успех ИИ — это локальный оптимум, а не финал»
 1ч 19м
1ч 19м🚀 Кэл Ньюпорт: «Системный подход — это суперсила»
 1ч 14м
1ч 14м🧠 Техлид Gemini 2.5 Джек Рэй о цепочках мыслей, латентном пространстве и пути к AGI
 1ч 36м
1ч 36м🛑 Эйсо Кант: «Вы не придете к AGI с помощью файн-тюнинга»
 1ч 56м
1ч 56м🧠 ИИ-саботаж и «интуитивная физика»: как будет выглядеть настоящий сверхразум
 53 мин
53 мин🚀 Якоб Фёрстер: «RL на GPU — наш момент ImageNet»
 24 мин
24 мин🧠 Сэм Альтман: «Сверхчеловеческий ИИ-кодер появится к концу 2025 года»
 34 мин
34 мин🤖 Уэс Рот: почему ИИ создает собственные «тайные» стратегии рассуждений
 3ч 31м
3ч 31м🧠 Как устроены LLM: от «зип-файла интернета» до рассуждающих моделей
 5ч 06м
5ч 06м🧠 DeepSeek: Как китайский хедж-фонд взломал монополию Кремниевой долины
 1ч 48м
1ч 48м🚀 DeepSeek-R1: Как Китай совершил революцию в рассуждениях ИИ
1ч 48м🧠 Натан Лаунд о DeepSeek: «Мы входим в эру сверхчеловеческого разума»
 25 мин
25 мин🚀 Уэс Рот о DeepSeek R1: китайский прорыв к сильному ИИ через самоэволюцию
 36 мин
36 мин🧠 Уэс Рот: как китайские лаборатории воспроизводят технологию рассуждений OpenAI
 28 мин
28 мин🤖 Использование физических моделей для обучения роботов ловкой манипуляции
 45 мин
45 мин🌡 Стэнфорд: три способа научить ИИ принимать решения через оценку градиента
45 мин🌡 Оптимизация стратегий в RL: три метода оценки градиента от Stanford Online
 35 мин
35 мин🚀 Почему будущее ИИ за логикой (Reasoning), а не просто масштабом
 1ч 13м
1ч 13м🧠 Стэнфордский университет: как самообучение и MCTS сделали AlphaGo непобедимым
 1ч 13м
1ч 13м🎲 Дэн Уэббер: «ИИ-хирург может убить одного человека ради спасения пяти, если он чистый утилитарист»
 1ч 19м
1ч 19м🚀 Профессор Бранскилл: «Обучение с подкреплением — это ключ к интеллекту»
 1ч 18м
1ч 18м🧠 Эмма Бранскилл о DQN: «Реплей-буфер — ключ к прогрессу»
 1ч 08м
1ч 08м🔄 Градиент стратегии и алгоритм REINFORCE: от робототехники до ChatGPT
 1ч 20м
1ч 20мМетоды оценки политики: Монте-Карло против Temporal Difference
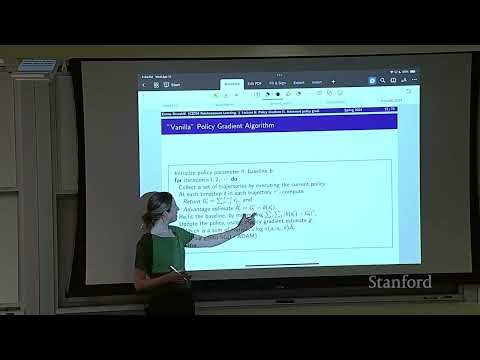 1ч 19м
1ч 19м🛡 Стэнфорд о PPO: «Почему это самый полезный метод в RL»
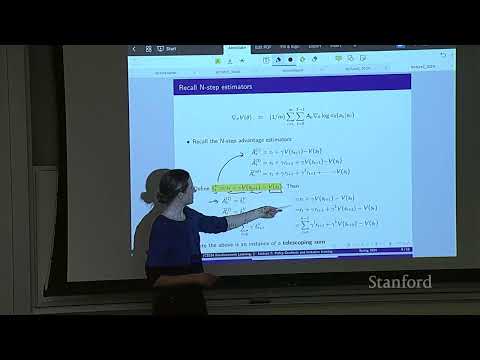 1ч 18м
1ч 18м🛠 От PPO до Dagger: современные методы обучения агентов
 14 мин
14 мин🕹 Как нейросеть научилась «грезить» игрой Doom без единой строчки программного кода
 1ч 39м
1ч 39м🧠 Юрген Шмидхубер: «Современные LLM — это не AGI»
 45 мин
45 мин🌍 Семинар в Стэнфорде: безопасное и эффективное обучение ИИ в физическом мире
 1ч 57м
1ч 57м🤖 Минки Цзян: «Следующий фронтир ИИ — это системы, которые сами задают вопросы»
 55 мин
55 мин📈 Ричард Саттон: «Ядро AGI может состоять всего из 10 000 строк кода»
 59 мин
59 мин🤖 Как искусственный интеллект меняет науку, медицину и искусство
 19 мин
19 мин🔬 NeurIPS 2023: Уязвимости ИИ, проблемы детерминизма и методы обучения
 45 мин
45 минЯнник Килчер о Q-Learning: «Возможно, это не связано с Q*»
45 мин🤖 Янник Килчер о Q-Learning: как ИИ учится принимать решения
 1ч 07м
1ч 07м🤖 Сергей Левин об эволюции обучения с подкреплением: от «бандитов» в ChatGPT до роботов-трансформеров
 45 мин
45 мин🚀 Тони Джебара о будущем: «Алгоритмы должны мыслить долгосрочно»
 55 мин
55 мин🎮 AlphaTensor: Как DeepMind ускоряет вычисления с помощью ИИ
 29 мин
29 мин🧱 Питер Шраммель из Diffblue: программисты тратят 35% времени на тесты, но ИИ готов взять эту рутину на себя
 44 мин
44 мин💡 ACCEL: как ИИ самостоятельно создает себе учебную программу
 42 мин
42 мин🧩 Янник Килчер: «Язык как ключ к эффективному обучению агентов»
 50 мин
50 мин🎮 Как ошибка в медиане влияет на оценку ИИ
 1ч 23м
1ч 23м🏗 Как победить в Minecraft RL: команда Kairos о сочетании обучения и инженерного подхода
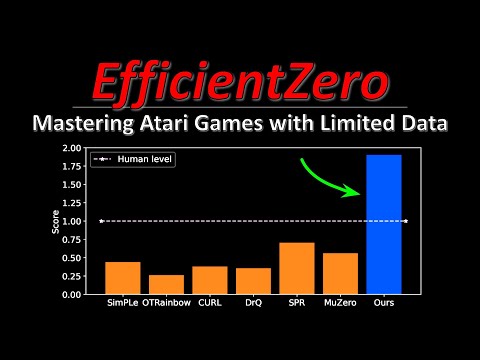 29 мин
29 мин🎮 EfficientZero: как ИИ учится играть в Atari почти без данных
 47 мин
47 мин🕹 Как классическая игра NetHack помогает обучать нейросети будущего
 43 мин
43 мин🕹 Как Electronic Arts использует глубокое обучение для создания и тестирования игр
 47 мин
47 мин💰 Гордон Ирлам: почему «правило 4%» проигрывает машинному обучению
 34 мин
34 мин🧠 AMP: как обучить ИИ-персонажей двигаться естественно?
 17 мин
17 мин🧠 Янник Килчер: «Эджлорды из Discord обошли техногигантов в демократизации ИИ»
 56 мин
56 мин🤖 Как превратить обучение с подкреплением в задачу для GPT: разбор Decision Transformer
 45 мин
45 минЯнник Кильхер о RIMs: «Это не мета-обучение, а разделение»
 1ч 05м
1ч 05м🤖 Питер Аббил: «Роботы должны учиться как дети»
 38 мин
38 мин🤖 Абхишек Гупта: «Мы должны выпустить роботов из лабораторий в наши дома»
 1ч 25м
1ч 25м🧬 Том Захави: «Обучение с подкреплением — самый общий фреймворк для AGI»
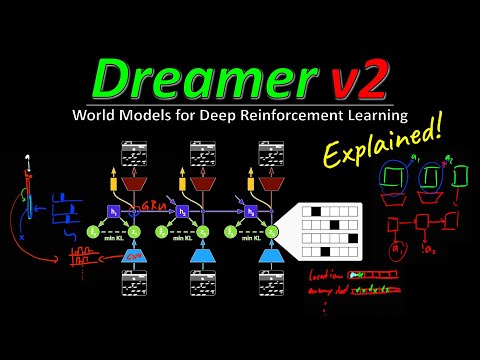 54 мин
54 минЯнник Килхер: «Dreamer v2 мастерски осваивает Atari в воображении»
54 мин🧠 Dreamer v2: как дискретные модели мира помогают ИИ побеждать в Atari
 58 мин
58 мин🎓 Гурдип Полл из Microsoft: «Мы строим Windows для автономных систем»
 40 мин
40 мин🤖 Пессимизм как стратегия: Аравинд Раджесваран о безопасности офлайн-обучения ИИ
 1ч 56м
1ч 56м🤖 Майкл Литтман: будущее ИИ и уроки обучения с подкреплением
 1ч 48м
1ч 48м🎰 Воутер Кулен о математике рекомендаций и «компиляторе исследований»
 43 мин
43 мин🍔 Гэри Рен из DoorDash: «ML предсказывает хаос, а математика находит из него выход»
 55 мин
55 мин🧠 Как решать новые задачи в RL без переобучения: разбор Янника Килчера
 38 мин
38 мин📊 Исследование Google Brain: как правильно настроить on-policy RL-агента
 24 мин
24 минЯнник Килчер о PCGRL: «Дизайн уровня как игра»
 1ч 37м
1ч 37м🧠 Почему роботы бьют посуду и как ИИ обретает здравый смысл
 50 мин
50 мин🤖 Янник Килхер о методе самостоятельного обучения навыкам ИИ
 1ч 38м
1ч 38м🧠 Харри Валпола: как обучить ИИ планированию и защитить его от системных иллюзий
 29 мин
29 мин🌍 Как заставить ИИ планировать только там, где он знает?
 10 мин
10 мин🕹 Как человеческая интуиция мешает и помогает нам в видеоиграх
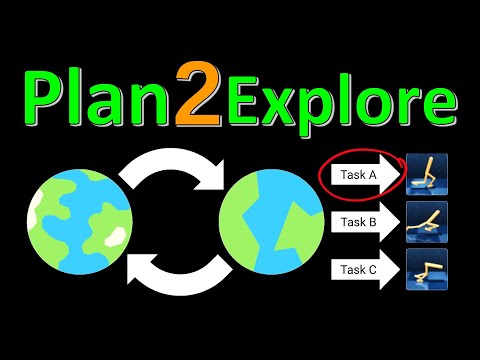 35 мин
35 мин🌍 Как обучить робота без вознаграждений? Разбор алгоритма Plan2Explore
 9 мин
9 мин🧩 Илья Суцкевер: «Зрение и язык — это одна и та же задача для ИИ»
 13 мин
13 мин🔄 Дэвид Сильвер о Deep RL: «В нейросетях с миллиардом параметров нет локальных минимумов»
 22 мин
22 мин🤖 Заменяет ли простая аугментация годы исследований в сфере RL?
 29 мин
29 минЯнник Килчер: как заставить роботов «думать на ходу»?
 1ч 14м
1ч 14м🚀 Тим Скарфе: «Почему самообучение нейросетей эффективнее человеческой разметки?»
 22 мин
22 мин🧱 Как научить робота крутить вентили за 10 кликов: разбор Dynamical Distance Learning
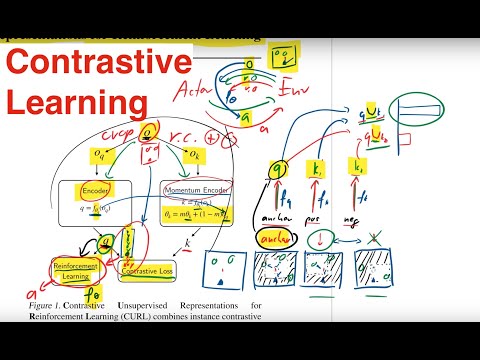 28 мин
28 минCURL: обучение ИИ на «сырых» пикселях без учителя
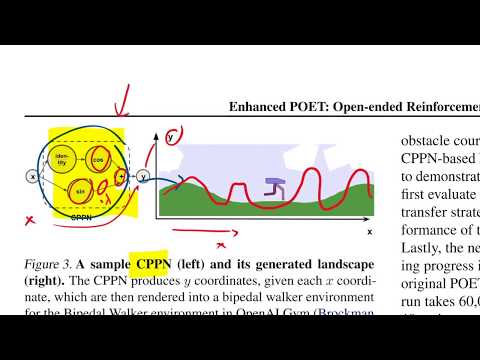 15 мин
15 мин🚀 Янник Килчер об Enhanced POET: «Бесконечная изобретательность ИИ в создании новых миров»
 22 мин
22 мин🤖 Dream to Control: подробный разбор обучения агентов в латентном пространстве
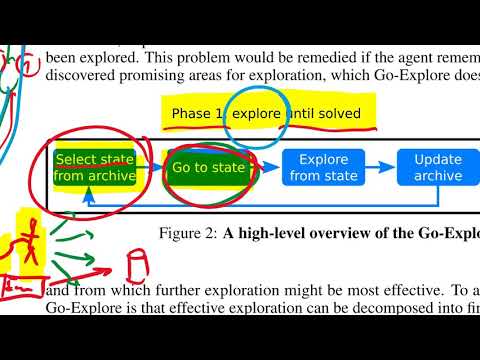 19 мин
19 минЯнник Кильхер о Go-Explore: «Новый подход к обучению ИИ»
 18 мин
18 минMuZero: как нейросети учатся планировать без правил игры
 37 мин
37 минЯнник Кильхер: «Преемственные представления — это ключ к пониманию мира агентами»
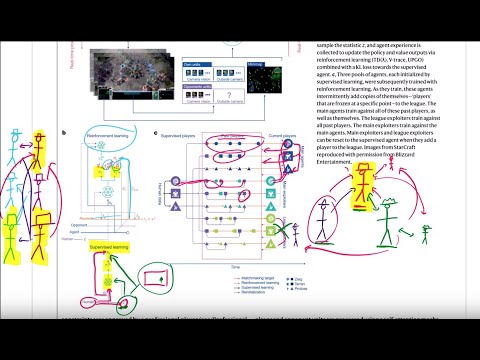 37 мин
37 мин🕹 AlphaStar: как ИИ достиг уровня Grandmaster в StarCraft II
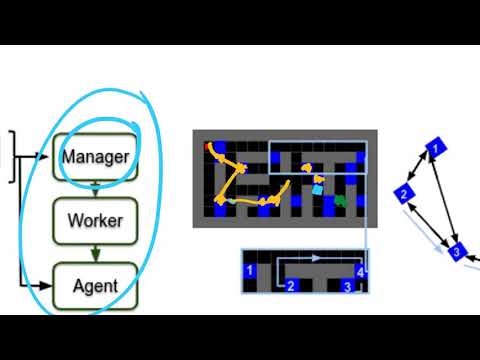 18 мин
18 мин🧱 Как Salesforce Research ускоряет иерархическое обучение с подкреплением через World Graphs
 1ч 38м
1ч 38м🤖 Дарио Амодеи об OpenAI, рисках AGI и о том, как попасть в индустрию безопасности ИИ
 18 мин
18 мин🧠 World Models: Как Дэвид Ха и Юрген Шмидхубер научили ИИ обучаться в собственном воображении
 17 мин
17 минЯнник Кильхер: как научить алгоритмы ИИ «любопытству»?
 10 мин
10 мин🧩 Обучение с подкреплением от Google: как вспомогательные задачи решают проблему редких наград
 15 мин
15 мин🤖 Янник Килчер объяснил работу агентов I2A от DeepMind
 24 мин
24 мин📱 Амнон Шашуа: «Вождение — это игра, в которой робот обязан научиться торговаться»